本文目标是搞清楚zlib库的deflate算法实现。
名词解释
deflate:最常见的无损压缩算法,非常关键。
.zip:archive format,使用了deflate压缩算法
.gz(或gzip格式): single file compress format,也是使用了deflate压缩算法
.tar.gz或.tgz:archive format,可认为.gz文件的集合,但又不止是多个.gz的集合,因为tgz利用了文件之间的关联信息,提升了压缩率。
zlib:一个通用库,只有源代码,不提供可执行文件,支持gzip。linux内核、libpng、git等等都用了它。
gzip:GNU Gzip,开源,提供了gzip和gunzip可执行文件,直接可以用来压缩、解压缩。内部也是实现了deflate算法。
7-Zip:类似gzip,也是工具。
经过了解,gzip的源码相对
Huffman Coding 和 LZ77
LZ77(Lempel–Ziv Coding)
LZ77是基于字典的算法。思路是,把数据中的重复(冗余)部分,用更短的metadata元信息代替。
wiki:LZ77 and LZ78
根据wiki所说,作者是发明了2个算法LZ77和LZ78。这2个算法是其他LZ算法变种的基础(LZW、LZSS、LZMA)。
下面重点介绍LZ77。
LZ77关键词:
- input stream:待压缩的字节序列串
- byte:字节,是input stream的基本元素
- coding position:相当于一个指针,指向当前编码位置;也是lookahead buffer的起始位置
- lookahead buffer:就是指coding position为起点,input stream末端为终点的这段字节序列
- window:最大长度为W的滑动窗口,也是以coding position为起点,但是窗口方向是反向往左;窗口初始长度为0,随着编码的进行,长度会增长到W,然后就开始往右滑动
- match:当前匹配串
- pointer:当前匹配串的信息,一般用(B,L)表示,B表示Go Back多少个字节(从coding position往左),因为也叫starting offset;L指匹配串从starting offset往右延伸的长度。 pointer为(0,0)时,表示匹配失败。
LZ77要注意的点:
- pointer的L是可能比B还大的,即匹配串从window区域,延伸进了lookahead buffer区域,又因为匹配串的起点就是lookahead buffer的起点,所以此时出现了repeat现象。这个repeat是没问题的,甚至是有用的,可以对不断重复的数据大大压缩。
- pointer有匹配成功和匹配失败2种情况,所以把pointer信息输出时,还得在pointer前用一个bit表示是哪种pointer。
- pointer里2个信息:B和L,它们的位数一般是固定的。位数大小可以是任意的N bits,但显然,位数太少的话,说明最大匹配长度就受限,即对于超长串是无法高度压缩的。
- 重点:有的文章会把pointer表示成(B,L,C)。C就是一个byte数据,这是因为任意一个byte第一次出现时,肯定是找不到匹配串的,所以会输出(0,0,byte);并且,为了输出缓冲区的结构一致性,当匹配成功时,也得输出(B,L,C),C相当于一个空的占位符,有点浪费,所以有的LZ77算法会再成功匹配后,把下一个byte存到占位符里,因此encoding position要移动L+1。(注意下文讲解的实例占位符是留空的)
- B和L耗用的位数不需要一样。
- 既然固定了B和L的位数大小,那么最大窗口大小W也是可以固定的,例如当W为32KB时,那么15 bits就可以表达32KB的任意一个值。
- window的最大长度W影响到压缩比率和压缩效率。显然W越大,匹配得越充分,但也越慢。
- 需要定一个最小匹配长度,只有当当前匹配串大于最小匹配长度时,这个匹配才成立。例如B用15位,L用8位,差不多就用了3个字节,如果当前匹配串不足3个字节,例如1个字节,那就导致encoding后长度反而更长了。
- 显然LZ77的compress做的工作量要比decompress多得多,因为做了大量的匹配查找。所以LZ77特别适合于一次压缩,多次解压缩的情景。
实例:
这种算法用实例来理解是最快的。微软这篇文章就给出了一个例子,这里拿来用一下。
(另外这篇文章给出了这个例子的示意图,建议同时参照下,本文就不做图了)
待压缩字节串(流):AABCBBABC
字节串中每个字节记一个位置标记position(上面的encoding position也是指这个),从1开始数,不是从0哦:
Position 1 2 3 4 5 6 7 8 9 Byte A A B C B B A B C
开始LZ77编码:
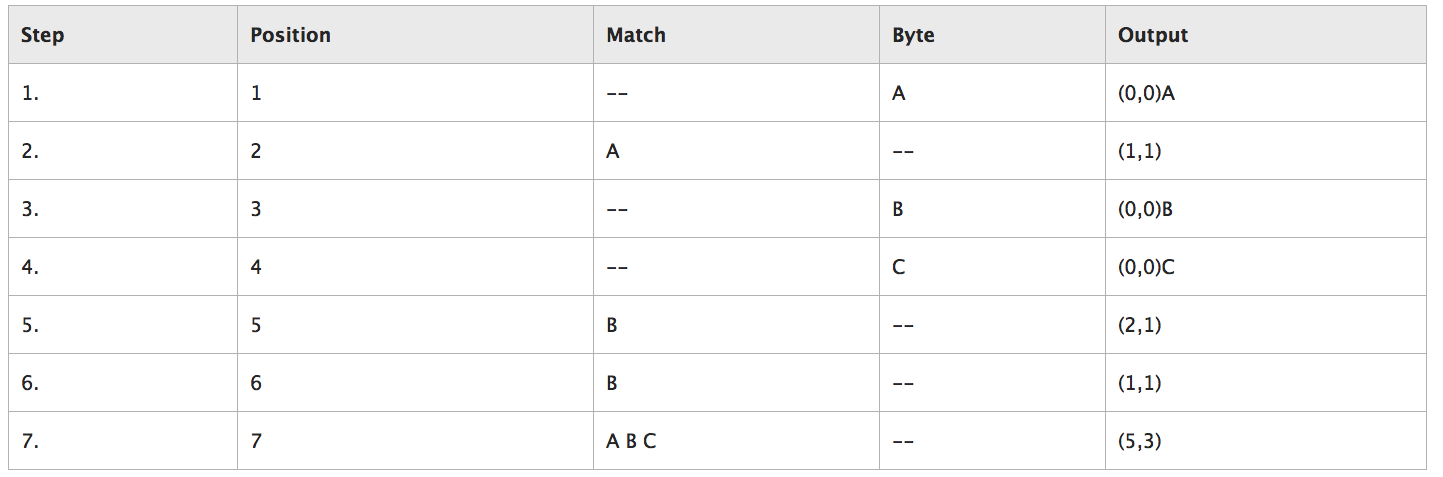
LZ77编码后,就输出了最右边一列,注意,这里只是方便理解,实际上不会存成文本形式,没有( ),这些字符。
这里重点要搞懂output这一列是怎么来的,用人话来描述下:
- 初始时,滑动窗口window是空的:【】
- 第1次遇到A,然后在window里match一下,必然找不到A,match失败,于是输出(0,0)A。window更新为【A】
- 第2次遇到A,window里match一下,此时要注意,match的方向是右到左(反向)。在window右起第1个位置就找到了A,所以输出(1, 1),window更新为【AA】
- 第1次遇到B,同步骤1,输出(0,0)B,window更新为【AAB】
- 同步骤3,输出(0,0)C,window更新为【AABC】
- 第2次遇到B,在window第2个位置找到B,于是starting position为2,同时发现下一个字节不匹配(左C和右B),所以长度为1,输出(2,1),window更新为【AABCB】
- 第3次遇到B,在window第1个位置就找到B,同时发现下一个字节不匹配(左B和右C),所以长度为1,输出(1,1),window更新为【AABCBB】
- 第3次遇到A,在window第5个位置找到A,然后迭代匹配,发现后面的BC也匹配上,所以长度为3,输出(5,3),window更新为【AABCBBABC】
接下来,看看如何把这一列output再解码回原文:
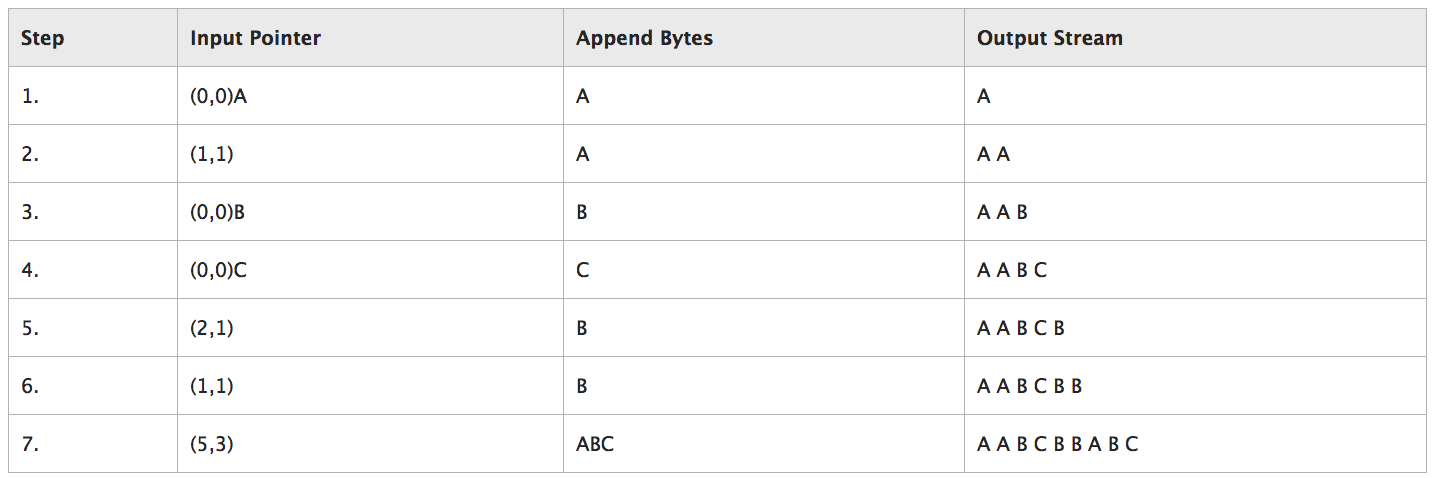
- 输入(0,0)A,表示直接往输出缓冲区push一个A字符。 【A】
- 输入(1,1),只有meta信息,(1,1)意思是它的位置等于1,长度为1,注意,位置是反向数,长度是正向数。显然,(1,1)等于缓冲区的字符A,于是push了一个一样的A。【AA】
- (0,0)B,和步骤1一样,直接push一个B。【AAB】
- (0,0)C,同上。【AABC】
- (2,1),又是meta信息,位置为2,长度为1,倒着数当前缓冲区,发现起点是B字符,长度为1,所以push一个B。【AABCB】
- (1,1),参考步骤5,也是push一个B。【AABCBB】
- (5,3),长度终于不为1了,首先在缓冲区倒着数5下,发现是左起第二个A,然后长度3,于是往右再获取2个字符,得到ABC,push到缓冲区,得到【AABCBBABC】
上面的内容搞得懂的话,就差不多了,要继续深入就是看源码。但不急,先看完Huffman Coding。
Huffman Coding
待续。
zlib 和 deflate
想直接看zlib的deflate代码是很难的。我发现一个入手方式是看doc/algorithm.txt 和 rfc1951还有deflate.c里的注释。
zlib
zlib自带CMakeLists.txt,在Mac上可以直接生成一个Xcode project,不仅可以方便地编译zlib,还可以用来学习zlib(本文的重心):
cd build/
cmake .. -G 'Xcode'
然后打开zlib.xcodeproj,构建All,并选择运行example。能运行成功的话打开example.c,会发现有完整的zlib使用教程。
我们重点放在deflate的最简单的使用实例:
test_deflate(compr, comprLen);
test_inflate(compr, comprLen, uncompr, uncomprLen);
第1行压缩,第2行解压。看懂了这两个函数代码,是理解deflate算法的第一步。
// 该函数用到的外部代码片段,我搬运到这里,方便浏览
// 压缩强度级别
#define Z_NO_COMPRESSION 0
#define Z_BEST_SPEED 1
#define Z_BEST_COMPRESSION 9
#define Z_DEFAULT_COMPRESSION (-1)
// 这个结构大概相当于一个压缩控制器
typedef struct z_stream_s {
z_const Bytef *next_in; /* 指向待压缩数据的第一个字节 */
uInt avail_in; /* 待压缩数据next_in的长度 */
uLong total_in; /* 当前已读取多少输入字节 */
Bytef *next_out; /* 指向输出缓冲区,只需要在一开始赋值一次 */
uInt avail_out; /* 输出缓冲区next_out的剩余空间 */
uLong total_out; /* 当前已输出多少输入字节*/
z_const char *msg; /* 错误信息 */
struct internal_state FAR *state; /* 暂时不用管这个 */
alloc_func zalloc; /* 压缩过程会分配新内存(internal state),用户可以设置自己的alloc函数给z_stream */
free_func zfree; /* 释放内存 */
voidpf opaque; /* zalloc、zfree的第一个参数,默认设0即可 */
int data_type; /* 数据的类型的猜测:Z_BINARY 或者 Z_TEXT,即保存了detect_data_type的返回值 */
uLong adler; /* 未压缩数据的检验和 (Adler-32 or CRC-32) */
uLong reserved;
} z_stream;
//待压缩的字节串
static z_const char hello[] = "hello, hello!";
void test_deflate(compr, comprLen)
Byte *compr;
uLong comprLen;
{
z_stream c_stream;
int err;
uLong len = (uLong)strlen(hello)+1; // 待压缩数据大小
c_stream.zalloc = zalloc;
c_stream.zfree = zfree;
c_stream.opaque = (voidpf)0;
err = deflateInit(&c_stream, Z_DEFAULT_COMPRESSION);
CHECK_ERR(err, "deflateInit");
c_stream.next_in = (z_const unsigned char *)hello;
c_stream.next_out = compr;
// 如果不使用1字节buffer模式的话,要执行这2行
// c_stream.avail_in = len;
// c_stream.avail_out = comprLen;
// 开始压缩
while (c_stream.total_in != len && c_stream.total_out < comprLen) {
c_stream.avail_in = c_stream.avail_out = 1; /* 每次只处理1个字节,故意的*/
err = deflate(&c_stream, Z_NO_FLUSH);
CHECK_ERR(err, "deflate");
}
// 压缩末端的处理
for (;;) {
c_stream.avail_out = 1; // 依然每次只输出一个字节
err = deflate(&c_stream, Z_FINISH);
if (err == Z_STREAM_END) break; // 结束标记
CHECK_ERR(err, "deflate");
}
err = deflateEnd(&c_stream);
CHECK_ERR(err, "deflateEnd");
}
纵观整个压缩流程,其实就是1个变量和3个函数:
- 定义z_stream局部变量c_stream
- deflateInit(&c_stream, Z_DEFAULT_COMPRESSION),初始化c_stream
- deflate(&c_stream, Z_NO_FLUSH)和deflate(&c_stream, Z_FINISH),压缩数据
- deflateEnd(&c_stream),结束
这个example故意让缓冲区每次迭代都只有1个字节可用,可以去掉那2行代码,并在开始压缩之前执行:
c_stream.avail_in = len;
c_stream.avail_out = comprLen;
接下来是解压缩:
void test_inflate(compr, comprLen, uncompr, uncomprLen)
Byte *compr, *uncompr;
uLong comprLen, uncomprLen;
{
int err;
z_stream d_stream;
strcpy((char*)uncompr, "garbage");
d_stream.zalloc = zalloc;
d_stream.zfree = zfree;
d_stream.opaque = (voidpf)0;
d_stream.next_in = compr;
d_stream.avail_in = 0;
d_stream.next_out = uncompr;
// 如果不使用1字节buffer模式的话,要执行这2行
// d_stream.avail_in = (uInt)comprLen;
// d_stream.avail_out = (uInt)uncomprLen;
err = inflateInit(&d_stream);
CHECK_ERR(err, "inflateInit");
while (d_stream.total_out < uncomprLen && d_stream.total_in < comprLen) {
d_stream.avail_in = d_stream.avail_out = 1;
err = inflate(&d_stream, Z_NO_FLUSH);
if (err == Z_STREAM_END) break;
CHECK_ERR(err, "inflate");
}
err = inflateEnd(&d_stream);
CHECK_ERR(err, "inflateEnd");
if (strcmp((char*)uncompr, mytest)) {
fprintf(stderr, "bad inflate\n");
exit(1);
} else {
printf("inflate(): %s\n", (char *)uncompr);
}
}
deflate和inflate函数的源码,非常恐怖,单个函数几百行。这里就不贴出来分析了。
deflate
待续。
adler32 和 CRC32
都是checksum,adler32速度比CRC32快,可靠性比CRC32逊色一点。zlib是为了兼容gzip,才保留了crc32。
checksum函数类似hash函数,但定位却很不一样。checksum函数主要针对错误检测和校正,而hash函数没有校正需求,且对hash值的碰撞容忍度,checksum要比hash高,有的hash甚至要求加密,如HMAC。
如果不考虑错误校正,确实可以用hash函数如MD5/SHA1来计算校验值,就是有点杀鸡用牛刀(overkill)。性能也比CRC32差,毕竟计算复杂。另外长度差距也很大,CRC32仅需要4个字节。
adler32对短消息处理得不好,因为短消息不能很好地覆盖到32bits,没有充分利用32bits。
历史
一位答主写了压缩算法的演变史,很值得一看:
简单来说,就是早期unix系统上面只有compress指令,compress使用了一个有版权的LZW算法,作者Phil Katz对LZW的免费使用有所争议。
并且,zip format也是这个作者设计的,但庆幸zip format是无版权的,于是就有个叫Info-ZIP group的组织开发了同样可以压缩&解压缩zip的程序,开源免费跨平台,这个东西导致zip format被大范围使用。
然后到了90年代早期,出现了新的压缩格式:gzip format(或.gz)以及对应的程序gzip。gzip的代码继承自Info-ZIP,gzip是打算用来取代unix的compress的。
gzip单个文件时,会给该文件加上.gz后缀。
然后又到了90年代中期,又遇到了版权问题,这次是关于gif格式的,gif用了带版权的LZW算法。于是又有人站出来开发了替代品:png。这是一种无损压缩图片的技术,同样使用了deflate作为内部格式。为了扩大png的使用范围,就弄出了libpng和zlib两个网站。libpng是用来处理png有关的所有事情,而zlib是作为libpng背后的支撑:提供了压缩和解压缩算法(当然现在也被用于别的软件)。注意,zlib的代码继承自gzip。
小结2点:gzip是zlib之父;以上说的版权问题现在都已过期了。
zlib兼容gzip,且提供了比gzip更多的功能选项。一是wrapping模式可选:无wrapping、zlib wrapping、gzip wrapping。无wrapping就是仅使用deflate内部格式;png使用的就是zlib wrapping。
zlib wrapping和gzip wrapping的主要区别是:zlib wrapping更紧凑并且新增了Adler-32算法,比gzip用的CRC32更快。
所以zlib源码会显得比较复杂,需要兼容gzip格式和CRC32,且新增了zlib格式和Adler32;gzip就显得比较原始,只有deflate和CRC32代码。
可以通过定义NO_GZIP宏,来关闭对gzip的兼容。默认是不定义的。如果定义了NO_GZIP,就只会使用alder32,没有crc32。
zlib是目前最广泛使用的压缩库。
再后来,就出现了新的基于deflate压缩库:7-Zip和google的zopfli。zopfli的压缩率比zlib的最高压缩率还高,压榨了最后的一些空间,但也花费了更多的CPU时间。当然这个最高压缩level是可选的。注意,zopfli只提供了压缩功能,解压缩依然得用zlib或gzip(大概是因为解压缩本来就足够优秀了);zopfli虽然有3-8%的压缩率提升,但耗时增长得更厉害,觉得zopfli还是显得鸡肋。
以上说的都是基于deflate算法的压缩库。实际上还存在别的算法:bzip2、LZMA等,他们有的甚至是完胜deflate。但很可惜,在互联网中要更替一种标准是非常困难的。deflate已经广泛运用到web的方方面面,难以取代。
所以还是学习deflate先吧。并且,阅读zlib库最佳。
资料
A Universal Algorithm for Sequential Data Compression
RFC1951 : DEFLATE Compressed Data Format Specification version 1.3
博主将十分感谢对本文章的任意金额的打赏^_^